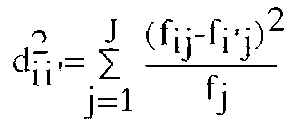| Correspondence Analysis | |||
Page 2 on 8 | Table of contents | Last | Next . |
|||
| 2. Overview of the
Method . |
|||
|
|||
. . A. |
. Suitable data type |
||
| Correspondence analysis is a method allowing you to
describe synthetically a contingency table in which homogenous individuals are classified
on two criterias (or categorical variables, continuos ones being usable if discretized). I
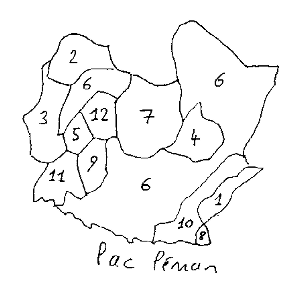
will use as an example the following table, in which 169'836 people aged 15 or more and
living in the Lausanne district (my hometown on the shore of Lake Geneva, in Switzerland,
see the map above) is attributed to one cell according to his maximum level of
schooling ever reached (variable I in rows) and community of residence
(variable J in columns. .
. The number in each cell of the table above stands for the number Kij of individuals who received the level of schooling i and living in the community j. For example we see that 244 people declared they had received no schooling at all in Renens. This is the raw data that will feed the correspondence analysis software. The aim of this analysis will be to find out if there is between rows and columns an attraction, independence or even repulsion, and to figure these relations graphically. But before understanding how the program works, we have to understand why. . . |
|||
B. |
A little bit of History of Linguistics On appelle distribution d'un mot l'ensemble de ses environnements possibles |
||
Correspondence analysis has been developed by the french-lebanese Benzecri at the end of the 60's for linguistic applications. We have to ponder the idea that was the inspiration of this method for a while. Opposed to Noam Chomsky, who thinks that it is impossible from a corpus (a sum of texts, like 10'000 pages) of an unknown language to determine its syntax and semantics inductively (that is, to rise by an explicit method from facts to the laws that govern them), linguists and statisticians worked jointly to prove Chomsky wrong. Suppose we already have separated phonemes and words, and that we are trying to determine the grammar (syntax) ant meaning (semantics) of these words. We are going to analyze tables like the following. Let I be a finished set of verbs (each verb a column). At the intersection of line i and column j we write the number k(i,j) of times that in a certain corpus the noun i was subject of verb j. If k(i,j) <> 0 then the verb j is a possible context for noun i and vice versa. That's how distributionnalist linguists define a grammatically correct phrase. We can go on and measure the relative importance for a noun i of the context j by the ratio f(i,j)=k(i,j)/k(i) with k(i) the sum of row i. The vector f(i,j) standing for the affinity between some noun i and all verbs j will be known as the profile i. Two nouns will be synonymous if they have the same profile, for two being that run, sing, and cough with the same frequency must be similar ! Practically we will never find two exactly similar profiles, so we are led to the problem of how to spatially represent the profile set. Benzecri chooses a criterion he named distributionnal equivalence principle to determine the formula used to compute the distance between two profiles. His thinking follows these lines : if two nouns i and i' are distributionnal synonyms (that is, they have the same profile) then if we replaced the two lines i and i' by a new line i'' sum of them, the distance between two given verbs j and j' must not change. So if for example ( to joke) used car salesman and crook have the same distribution, we could identify them and write a single line for both in our table. This principle, assorted by the mathematical requirement of quadraticity for the distance formula (i.e. we want a sum of squares) suffices to fix the distributionnal distance. Distributionnal distance known as
What should you remember from this digression ? The essential is the idea that in correspondence analysis, like the meaning of a word is revealed by its context, the meaning of an item or of a characteristic will appear through its associations as shown by the analysis. . Note for sociologists: in sociology, as used by Pierre Bourdieu and the academics writing in Actes de la Recherche en Sciences Sociales, this method is of structuralist inspiration. Its origin, outlined above, let you guess that, and you will see further that the objects it describes are mainly, yes, relations. . |
|||
| |
|||